Kubernetes is a domain specific database
I just finished listening to an episode of the Kubernetes podcast. In it, Thomas Rampelberg makes an analogy that I think is worth sharing:
"[...] Kubernetes is really a domain-specific database. And you need to look at it that way. The YAML is literally writing a select statement or an insert statement for a database. That's what the YAML is. And it's awesome that it is already configured for how it is. And it's awesome that it's got a schema. But the YAML is you writing an insert statement into Kubernetes. [...]"
The Kubernetes API abstracts two types of states: desired state and actual state. Whenever you apply a manifest, you update the desired state of the cluster, just like you do in a regular, non domain-specific database like PostgreSQL or Redis. Kubernetes then frequently compares the desired state with the actual state of the cluster. If they don't match, Kubernetes will do whatever it does to match these two states. Usually, this data is persisted using a key-value database like etcd running in a cluster, though one could theoretically also hook up an external MySQL or Postgres database for this purpose.
I found this great diagram by Tim Downey, showing an oversimplified analogy of this pattern:
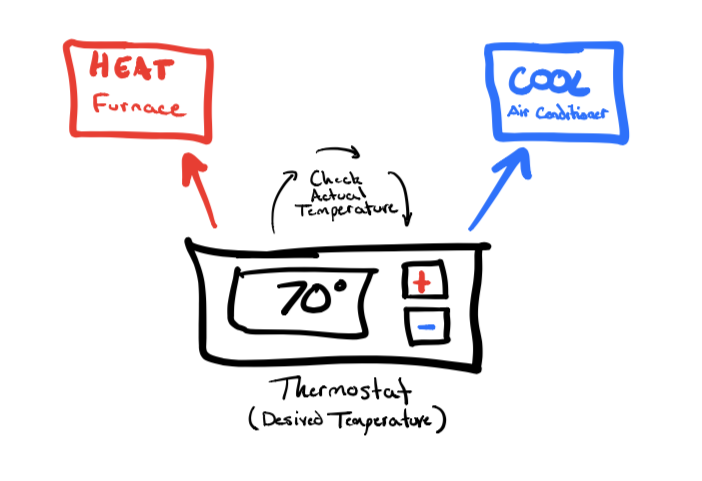
You insert your desired state into the system, and the system adjusts the actual state to match the desired state. In the case of thermostats the state is a temperature. In Kubernetes, it's resource objects
This is post 037 of #100DaysToOffload.